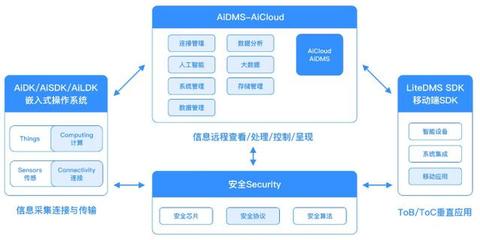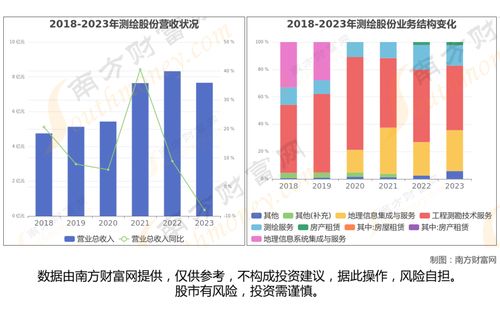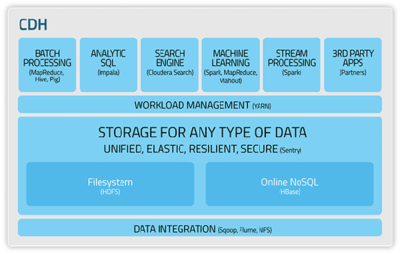
隨著大數(shù)據(jù)技術(shù)的快速發(fā)展,以Hadoop為核心的經(jīng)典生態(tài)系統(tǒng)已不再是唯一選擇。我們正步入一個(gè)被稱為“后Hadoop時(shí)代”的新階段,其標(biāo)志是更靈活、更高效、更云原生的架構(gòu)與數(shù)據(jù)處理技術(shù)的崛起。這一演變并非對(duì)Hadoop的全盤否定,而是對(duì)其理念的繼承、補(bǔ)充與超越。
一、 架構(gòu)演進(jìn):從單一批處理到混合與云原生
傳統(tǒng)Hadoop架構(gòu)(HDFS + MapReduce + YARN)以其高容錯(cuò)、高擴(kuò)展性和低成本處理海量批數(shù)據(jù)的優(yōu)勢(shì),奠定了大數(shù)據(jù)的基礎(chǔ)。其架構(gòu)也存在著實(shí)時(shí)性不足、運(yùn)維復(fù)雜、資源調(diào)度不夠靈活等挑戰(zhàn)。后Hadoop時(shí)代的架構(gòu)呈現(xiàn)出以下核心趨勢(shì):
- 批流融合與Lambda/Kappa架構(gòu)的演進(jìn):為應(yīng)對(duì)實(shí)時(shí)數(shù)據(jù)分析的需求,Lambda架構(gòu)(批層+速度層)一度流行,但其維護(hù)兩套系統(tǒng)的復(fù)雜性催生了更簡(jiǎn)化的Kappa架構(gòu)(基于單一流處理層)。如今,以Apache Flink為代表的系統(tǒng),憑借其真正的流批一體引擎,正成為統(tǒng)一數(shù)據(jù)處理的標(biāo)桿。它允許用戶在同一個(gè)框架內(nèi)無縫處理實(shí)時(shí)流和歷史批數(shù)據(jù),極大地簡(jiǎn)化了架構(gòu)和開發(fā)運(yùn)維成本。
- 解耦與云原生:Hadoop將存儲(chǔ)(HDFS)與計(jì)算(MapReduce)緊密耦合。現(xiàn)代架構(gòu)則傾向于存儲(chǔ)與計(jì)算分離。對(duì)象存儲(chǔ)(如AWS S3、Azure Blob Storage)因其無限擴(kuò)展、高持久性和低成本,成為數(shù)據(jù)湖的通用存儲(chǔ)層。計(jì)算引擎(如Spark、Presto、Flink)可以按需彈性伸縮,從分離的存儲(chǔ)中讀取數(shù)據(jù),實(shí)現(xiàn)了更高的資源利用率和靈活性,完美契合云環(huán)境的按需付費(fèi)模式。Kubernetes等容器編排技術(shù)的普及,進(jìn)一步推動(dòng)了大數(shù)據(jù)工作負(fù)載的容器化與云原生化部署。
- 數(shù)據(jù)湖、數(shù)據(jù)湖倉(cāng)與數(shù)據(jù)網(wǎng)格:
- 數(shù)據(jù)湖 作為集中式存儲(chǔ)原始數(shù)據(jù)的倉(cāng)庫(kù),概念得以延續(xù)和優(yōu)化。
- 數(shù)據(jù)湖倉(cāng)(Lakehouse),如Databricks提出的Delta Lake、Apache Iceberg和Apache Hudi,在數(shù)據(jù)湖之上添加了類似數(shù)據(jù)倉(cāng)庫(kù)的事務(wù)管理、模式約束和性能優(yōu)化能力,試圖融合數(shù)據(jù)湖的靈活性與數(shù)據(jù)倉(cāng)庫(kù)的管理治理優(yōu)勢(shì)。
- 數(shù)據(jù)網(wǎng)格(Data Mesh)則是一種去中心化的社會(huì)技術(shù)范式,它強(qiáng)調(diào)將數(shù)據(jù)所有權(quán)賦予業(yè)務(wù)領(lǐng)域團(tuán)隊(duì),通過產(chǎn)品化思維提供數(shù)據(jù),并通過標(biāo)準(zhǔn)化平臺(tái)實(shí)現(xiàn)自助服務(wù)和聯(lián)邦治理,以應(yīng)對(duì)大規(guī)模、多領(lǐng)域數(shù)據(jù)的組織挑戰(zhàn)。
二、 數(shù)據(jù)處理技術(shù)的多元化生態(tài)
數(shù)據(jù)處理引擎不再被MapReduce所主導(dǎo),形成了一個(gè)各司其職、性能卓越的多元化生態(tài):
- 批處理:Apache Spark憑借其內(nèi)存計(jì)算、DAG執(zhí)行引擎和豐富的API(RDD, DataFrame, SQL, MLlib),在批處理領(lǐng)域已基本取代MapReduce,成為事實(shí)標(biāo)準(zhǔn)。其性能提升可達(dá)數(shù)個(gè)數(shù)量級(jí)。
- 流處理:Apache Flink(低延遲、高吞吐、精確一次語(yǔ)義、狀態(tài)管理)、Apache Kafka Streams(輕量級(jí)、直接集成Kafka)和Apache Spark Structured Streaming(基于微批,與Spark生態(tài)無縫集成)構(gòu)成了流處理的核心陣營(yíng)。特別是Flink,在實(shí)時(shí)風(fēng)控、實(shí)時(shí)推薦等場(chǎng)景中表現(xiàn)突出。
- 交互式查詢:Presto/Trino(高性能、ANSI SQL支持、多數(shù)據(jù)源聯(lián)邦查詢)和Apache Impala(針對(duì)HDFS/Hive的MPP查詢引擎)使得在龐大數(shù)據(jù)集上進(jìn)行亞秒級(jí)到秒級(jí)的即席查詢成為可能,極大地提升了數(shù)據(jù)分析師的效率。
- 數(shù)據(jù)攝取與變更數(shù)據(jù)捕獲(CDC):Apache Kafka作為分布式事件流平臺(tái),已成為實(shí)時(shí)數(shù)據(jù)管道的骨干。Debezium等CDC工具能夠?qū)崟r(shí)捕獲數(shù)據(jù)庫(kù)變更并流入Kafka,是實(shí)現(xiàn)實(shí)時(shí)數(shù)據(jù)同步和湖倉(cāng)一體化的關(guān)鍵技術(shù)。
- 事務(wù)性與數(shù)據(jù)管理:如前所述,Delta Lake、Iceberg、Hudi這些開源表格式,為云存儲(chǔ)上的海量數(shù)據(jù)提供了ACID事務(wù)、時(shí)間旅行、模式演進(jìn)等關(guān)鍵能力,是構(gòu)建現(xiàn)代數(shù)據(jù)架構(gòu)的基石。
三、 與展望
后Hadoop時(shí)代的大數(shù)據(jù)架構(gòu),核心特征是 “多元化”、“解耦化”、“云原生化”和“實(shí)時(shí)化” 。技術(shù)選型不再依賴單一平臺(tái),而是根據(jù)具體場(chǎng)景(實(shí)時(shí)/離線、吞吐/延遲、成本/性能)組合最佳工具鏈。未來的發(fā)展將聚焦于:
- 智能化與自動(dòng)化:AI for DataOps,實(shí)現(xiàn)數(shù)據(jù)治理、質(zhì)量監(jiān)控、性能優(yōu)化的自動(dòng)化。
- 統(tǒng)一與簡(jiǎn)化:盡管技術(shù)棧多元,但通過SQL標(biāo)準(zhǔn)化、統(tǒng)一元數(shù)據(jù)層(如Apache Atlas、DataHub)和一體化平臺(tái)(如云廠商的托管服務(wù)),降低用戶的使用和運(yùn)維門檻。
- 實(shí)時(shí)與決策閉環(huán):流處理技術(shù)將進(jìn)一步滲透,推動(dòng)從“事后分析”到“實(shí)時(shí)洞察與行動(dòng)”的轉(zhuǎn)變,構(gòu)建更短的數(shù)據(jù)價(jià)值閉環(huán)。
后Hadoop時(shí)代是一個(gè)百花齊放、注重實(shí)效的時(shí)代。Hadoop的遺產(chǎn)——分布式、可擴(kuò)展的思想——已融入血液,而新的架構(gòu)與技術(shù)正驅(qū)動(dòng)著大數(shù)據(jù)走向更易用、更強(qiáng)大、更具業(yè)務(wù)價(jià)值的未來。